如何微调一个大语言模型
文章目录
在当今的数字化时代,大语言模型的发展正在以前所未有的速度推动着人工智能领域的进步。大语言模型,也称为大型预训练语言模型,代表了人工智能语言处理领域的一种突破。国外的有OpenAI的ChatGPT,Google的Bard,Anthropic的Claude;国内的有百度的文心一言,智谱AI的智谱清言,讯飞的星火大模型。这些都是闭源的大模型,提供了一个应用程序供使用。
现在,许多公司和研究机构都在落地大语言模型。都在尝试把大语言模型部署到企业内部,让企业内部的数据可以更加智能的利用起来。落地的方式有两种:一种是调用各大公司提供的API接口,快速把大模型的能力接入到企业内部;另外一种方式是部署开源大模型。第一种方式适合无企业敏感数据,迫切希望接入大模型的智能;而第二种针对企业的敏感数据,不希望敏感数据流出企业。
引言
本文针对企业落地大模型的第二种方式,谈一谈如何构建一个可以运行大模型和训练大模型的环境,这是企业落地大模型的第一步。
下面我们以构建一个可以使用**LLaMA-Efficient-Tuning**来微调大语言模型的镜像为例来说明。
如果你服务的企业有足够好的硬件及网络条件,同时在物理机上有安装软件的权限,那么建议你直接在物理机上安装驱动、依赖、下载微调源码,下载模型,然后进行微调。
下面介绍的流程更多的是在网络条件不允许的情况下,把所有东西都放在Docker里面是十分方便的一种做法,只需要企业内部的服务器支持Docker的运行和安装了nvidia驱动的机器即可。
构建镜像
LLaMA-Efficient-Tuning这个开源项目已经集成了非常多的开源模型的微调,比如流行的ChatGLM2,LLaMA-2等待。开箱即用,简直不要太方便。官方还提供了非常多实用的数据集
克隆项目源代码 git clone https://github.com/hiyouga/LLaMA-Efficient-Tuning.git
本文只构建训练用的Docker镜像环境,所以只需要requirements.txt的内容即可,把依赖的模块全部安装上,requirements.txt内容如下:
|
|
最好是创建一个目录,把requirements.txt放在创建好的目录下面,从这个目录启动一个docker容器:
|
|
本文以pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel Docker镜像为基础镜像进行构建,运行完上面的命令,你会进入到容器的/build目录,这个目录下面就可以看到requirements.txt文件。这是一定要加上—-gpus=all 参数。同时还要注意,物理机上必须要安装nvidia的驱动,移步官网下载安装。

然后使用下面的命令安装依赖
|
|
指定了使用清华的镜像源,安装起来会快很多。
最后,需要把运行的容器保存为镜像:
|
|
这时我们获得了一个可以运行LLaMA-Efficient-Tuning的Docker镜像了。
微调
什么是微调呢?微调语言模型涉及在较小的、特定于任务的数据集上训练模型,以适应特定的任务或领域。预训练的基础模型充当起点,网络的权重将根据特定于任务的数据进一步优化。微调有助于模型更好地理解它正在微调的任务的特定上下文和语言模式。
本文以微调ChatGLM2-6B为例,介绍如何使用LLaMA-Efficient-Tuning进行预训练、指令监督、奖励模型以及PPO和DPO训练的微调。
上面我们下面了LLaMA-Efficient-Tuning源码。同时我们还需要下载ChatGLM2-6B的源码,下载后我们放在/LLaMA-Efficient-Tuning/base_models/chatglm2-6b目录。
下载链接:https://huggingface.co/THUDM/chatglm2-6b
预训练
预训练微调的过程是一个自监督训练的过程,使用非结构化的文本进行训练,下面是 data/wiki_demo.txt 的训练数据内容:
然后我们创建一个/LLaMA-Efficient-Tuning/pretrain.sh的脚本文件,来对预训练进行微调,内容使用官方提供的参数,做几个地方的修改:
|
|
在官方内容基础上修改了model_name_or_path、lora_target以及output_dir三个参数的值。这里使用的训练数据是LLaMA-Efficient-Tuning自带的示例数据data/wiki_demo.txt,如果你有自己的企业私有数据,按照这个格式,把内容放到里面即可。
所有的数据集在data/dataset_info.json文件里面都有定义,运行的命令里面使用数据集的名称即可。也可以自己添加私有的数据集。
我们在命令行下可以看到整个训练的过程
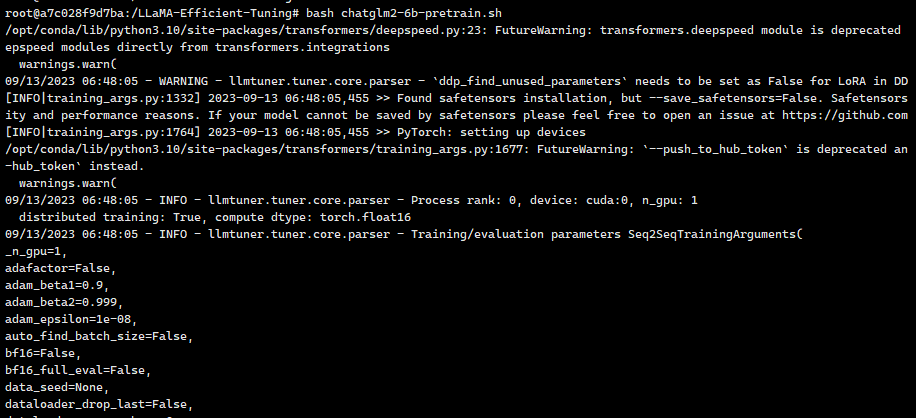
上图可以看到训练的所有超参数信息

上图可以看到加载训练数据,模型的参数等信息
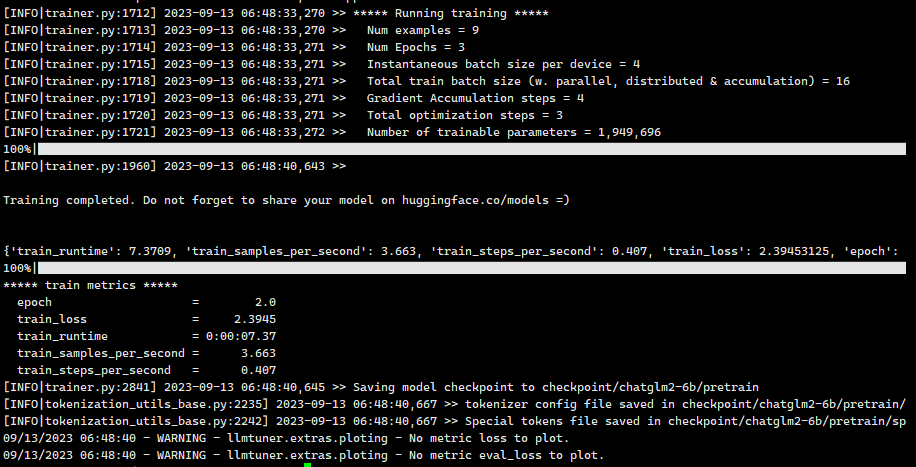
上图可以看到训练完成后的一些metric值,像训练的loss值,运行时间,训练速度,迭代数epoch,checkpoint保存的目录等信息。
导出微调后的模型
预训练模型是一个基础模型,后续的微调如果要基于微调后的预训练模型的话,需要把原始的基础模型和微调后的checkpiont进行合并,然后导出为一个完整的模型。
使用下面的命令可以导出预训练微调后的模型:
|
|
指令监督微调
指令监督微调是ChatGPT的训练过程当中的SFT阶段(这里请参考InstructGPT那篇论文[2]),通过人工标注的指令集,让大语言模型生成指令相关的回答内容,数据集类似下面这样:
同样,我们新建一个shell脚本/LLaMA-Efficient-Tuning/sft.sh,在官方给的参数上修改几个参数,运行这个脚本进行SFT微调:
|
|
上面的SFT微调是基础ChatGLM2-6b基础模型的训练,如果在上面对预训练做了微调,那么model_name_or_path就需要指定为上面导出的模型。
其他的几个阶段的训练就不一一列举了,可以到github仓库查看。下面来看看如何使用多GPU来并行训练。
多GPU分布式训练
运行accelerate config 命令来配置分布式环境
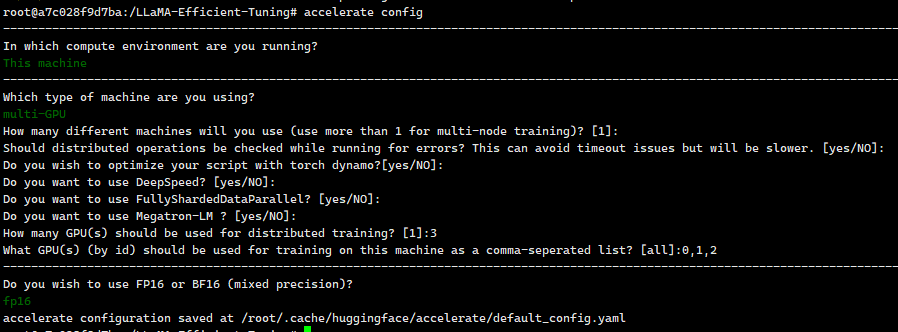
运行上面的命令后会在生成一个配置文件:/root/.cache/huggingface/accelerate/default_config.yaml
配置文件内容如下:
|
|
然后使用accelerate launch src/train_bash.py 命令,加上上面每个步骤的训练参数即可使用分布式训练了。
完整的分布式训练命令如下:
|
|
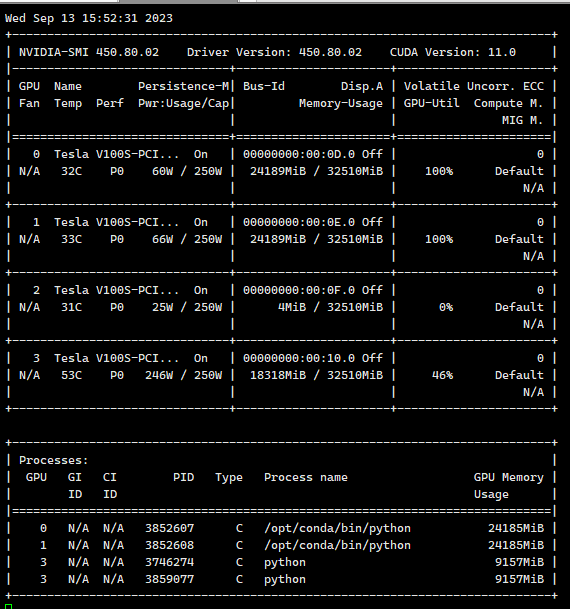
在配置文件里面我们设置了使用2个GPU来进行训练,上图可以看到第0、1块GPU占用了大概24G的显存(第3块GPU是在跟其他任务)
模型评测
LLaMA-Efficient-Tuning提供了完整的工具链,同样也提供了非常优秀的开箱即用的评测程序。
评测我们也来创建一个shell脚本/LLaMA-Efficient-Tuning/eval.sh,可以重复执行:
|
|
这里使用了alpaca_gpt4_zh这个数据集来进行评测SFT模型,运行的结果如下:
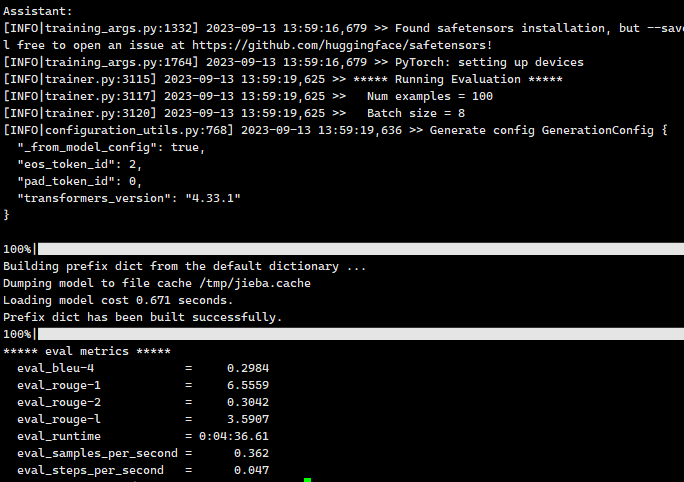
可以看到BLEU 分数和ROUGE 分数。
总结
本文从企业落地大语言模型出发,以LLaMA-Efficient-Tuning工具链和ChatGLM2-6B模型为例,介绍了如何训练与评估大语言模型。开箱即用的体验使得LLaMA-Efficient-Tuning工具链非常的流行。后面会持续撰写如何开发基于大语言模型的企业级应用,以及开源各种应用源码。
公众号
欢迎关注我的公众号,同步更新
