使用ChatGPT在指定数据集上进行对话
文章目录
ChatGPT不全面简介
ChatGPT是一种基于预训练的自然语言生成模型,是GPT系列模型的一种。ChatGPT的论文并没有公开发表,最相关的一篇工作就是InstructGPT(Training language models to follow instructions with human feedback)了,发表时间是2022年3月4日。
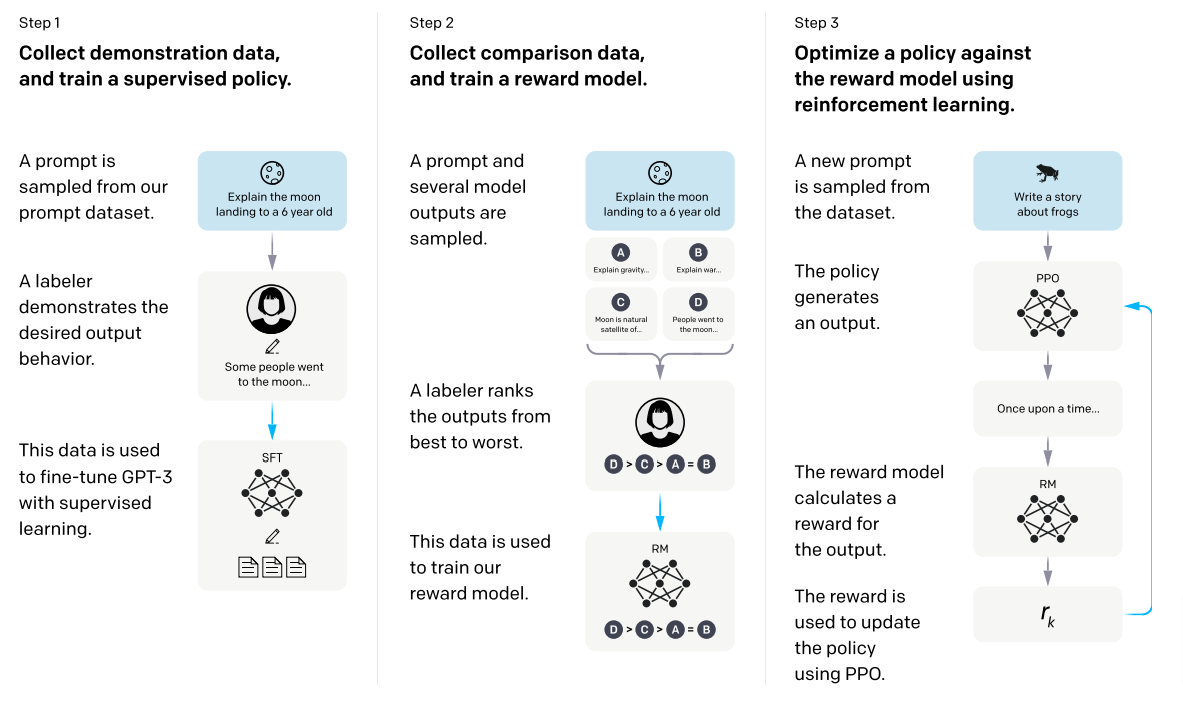
InstructGPT基于GPT-3.5来训练的,但是GPT-3.5官方并没有释放出来。InstructGPT是结合了RLHF(reinforcement learning from human feedback)(Christiano et al., 2017; Stiennon et al., 2020)—基于人工反馈的强化学习方法 — 训练出来的文本生成模型。
上面的图展示了InstractGPT训练的三个过程:
- 从prompt数据库当中采样prompt列表,通过人工标注,用于对GPT-3进行微调;
- 训练强化学习的奖励模型,采用的方法是输入prompt到多个模型,人工标注生成的内容的相关性;通过标注的相关性数据训练奖励模型;
- 使用奖励模型来优化InstructGPT models (PPO-ptx)。
在指定数据集上进行对话
什么意思呢?举个栗子,给定你一个文本文件,让ChatGPT根据给定的文本内容来回答你提出的问题。下面看一个具体的例子,我在阅读InstructGPT的论文的时候,英文不太好,摘要不想,就让ChatGPT告诉我摘要在讲什么,还得中文回答我:

看这个回答还是太长了,我得让他再精简一点,要求50个字讲清楚:

虽然对字段的精确理解还差了一些,但确实短了不少😄。
现在来讲一下大概的原理。GPT模型本身就是一个In-context learning的过程,可以根据给定的上下文,生成与上下文非常相关的内容。
有了这个原理,我们就有思路了,如果是一个给定的数据集,而不是一段文本呢?另外,还有一个信息非常重要,我们是使用OpenAI的官方API(gpt-3.5-turbo模型)来实现这个demo,OpenAI的API的token数量是有限制的,所以上下文的内容长度是有限制的。那么很明显了,需要把问题和问题相关的文本块要像上面那样去组织,然后丢给OpenAI的API来回答即可。
流程图
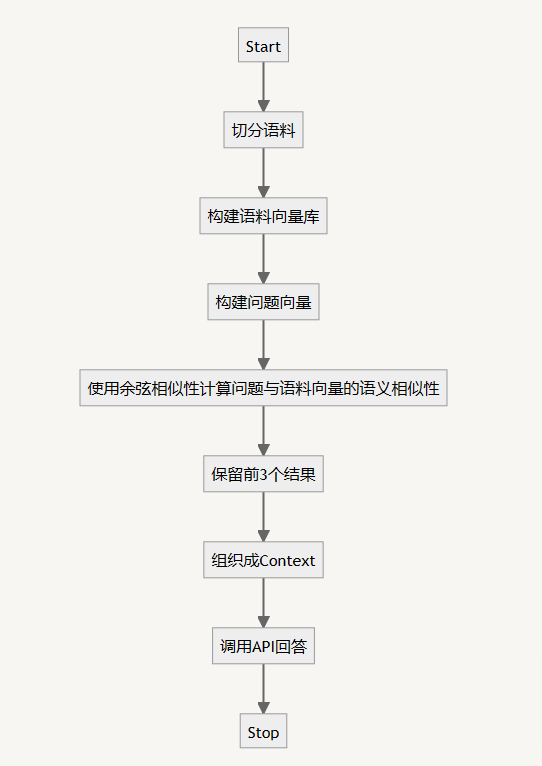
我们来画个流程图
分步骤实现
首先把准备的语料切分成文本块,官方给的例子是按句子进行切分,然后合并相邻的两个句子,如果合并后的长度在500个token以内就保留合并的内容,如果超过这个阈值就不合并。
|
|
这个split_into_many函数就是对一大段文本进行切分用的,按照. 分割文本,分割后以max_tokens为阈值进行合并。最后返回文本块数组。
有了文本块数组之后,调用OpenAI的API接口,把每个文本块变成一个向量。
先来看embedding函数:
|
|
embedding函数非常简单,调用openai.Embedding.create函数就能得到一个文本的向量表示了。
|
|
这里需要一个tiktoken包,来对文本进行token的切分(注意这里的token不是分词,而是WordPiece tokenization)。convert_embeddings接收一个文本,然后返回一个文本列表、每个文本token数量,以及文本的向量表示。
接下来就是把问题表示成向量,组织context了
|
|
这是首先调用OpenAI的API把问题文本变成向量。把上一步生成的语料向量变成pandas的DataFrame(便于计算),调用distances_from_embeddings计算问题向量和语料向量里面每个文本向量的余弦相似度,按照相似度降序列表候选答案,使用换行以及###合并多个候选答案文本。
最后一步,很关键的一步,调用OpenAI接口在候选答案中生成回答内容:
|
|
这里很重要的一点就是prompt的设计。Answer the question based on the context below这一句首先在限定答案来源,if the question can't be answered based on the context, say "I don't know"这一句提示模型在不能回答的时候输出i don’t know,接着把Context和question付在后面。
见证奇迹的时刻
后面就是见证奇迹的时刻了,我做了一个demo,可以上传pdf,然后可以问任何关于pdf内容的问题

结论
大模型时代的到来,人工智能离我们越来越近,各种应用肯定会如雨后春笋般涌现。OpenAI开放了更多更强的API也给了我们更多的瞎想和可能性。OpenAI开发的ChatGPT可以实现
- 相应用户输入并生成类似人类的文本;
- 可生成多种格式和样式的文本,例如段落、列表和要点;
- 帮助程序员调试代码或给出建议;
- 提供时事、历史、科学等各种主题信息。
ChatGPT是一种基于预训练的自然语言生成模型,属于GPT系列模型之一,具有广泛的落地场景和发展潜力。未来,它可以与图形模态的AIGC相结合,打造从文字描述到图片生成的AI辅助工具。ChatGPT的上线推动了文本类AI在文本生产、智能批阅等应用领域的发展,并且对训练模型的改进具有广泛的意义。
服务
如果您有集成AI服务的需求,请联系我,对我还不了解?没有关系,请阅读我的简历,希望可以与您合作 ^_^