Solr集群索引以及查询对负载的影响
文章目录
今天对Solr 7.6.0的集群的索引以及查询对负载的影响做一点测试,记录一下测试结果。
collection的shards和leader分布情况如下
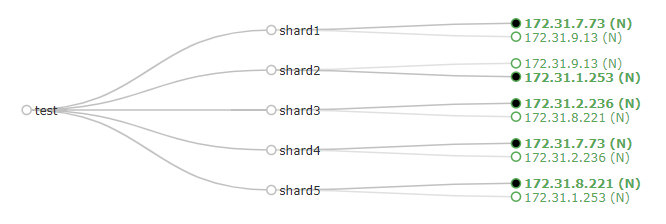
ip和name对应如下表:
| ip | name |
|---|---|
| 172.31.1.253 | solr1 |
| 172.31.7.73 | solr2 |
| 172.31.2.236 | solr3 |
| 172.31.8.221 | solr4 |
| 172.31.9.13 | solr5 |
索引
测试的点是往没有leader的机器发文档进行索引,统计到的cpu utilization如下图。

从图中可以看出,发往没有leader的机器进行索引,所有机器的cpu都差不多。从而推论不管往哪个机器发文档进行索引,各个机器的cpu utilization都是均匀的。
索引数据如下:
|
|
下面是索引中文时机器的cpu指标,中文使用单字分词,有title, content。content字段字符数量大概在1000-2000之间。索引时间在5-60秒不等。每一批为100条数据。

从图中可以看到solr5(接收请求)机器负载稍微高一点点。
查询
使用的查询数据为随机生成的200000个关键词,间隔200毫秒。collection里面的数据量在10000左右。

上图分成三个区间来看:15:30之前,15:30-16:05,16:05之后,每一个区间使用不同的查询方法。
另外,solr5那个机器是没有leader在上面的。
15:30之前
这个时间区间使用的是所有请求串行发送,也就是一个接一个的发送,CPU的负载整体都不是很高,所有请求都发送到solr5那个机器上面,很明显的看到solr5机器的cpu负载要高于其他机器,其他机器的负载差不多。
15:30-16:05
这个时间区间使用跟上面一样的方法,只是并发数为10,请求也是只发送到solr5机器上面。可以看到solr5的负载明显高于其他机器。其他4个机器负载差不多。
16:05之后
这个时间区间使用同样的查询数据,10个并发,请求发送到solr1上面。从图上可以看到solr1的负载要高于其他4个机器,其他4个机器负载差不多。这一个测试的结果说明,不管一个节点上有没有leader,这个机器都会去比承担一部分的查询请求。
结论
索引的时候各机器的负载差不多。查询的时候,请求的机器负载高于其他机器,其他机器负载相差不大。所以要集群查询的时候可以使用轮询的方式,每一次查询请求可以发送到不同的机器,这样就可以保证所有机器的负载相当了。